

Author: John Ormerod
Date: August 2016
Contents
What is a Multi-tier Architecture? 5
Why is a multi-tier architecture so effective? 6
Characteristics of a Microservice 9
How do Microservices and a Multi-tiered Architecture Fit Together? 9
Re-use and Change when using an API-led Tiered Architecture 10
Re-use and Change when using Microservices 11
How do Microservices differ from an API-led Architecture? 12
WHY and When? (Should Microservices be Adopted) 14
The use of a separate data store per microservice 16
Introduction
This paper uses terms and acronyms, such as: API, service, microservice, MVC, tier, loosely coupled and bimodal IT; the majority of these terms are explained in the body.
Throughout the history of IT, trends have been followed in IT development, together with game-changing ideas that have made a real difference to the way developers and architects think about how they design and develop systems.
The pressure on organisations from customers to provide services in multiple ways by ‘yesterday’ is forcing organisations to find new ways to develop and change their service offerings in an accelerated manner. In response, two game-changing ideas have emerged: microservices and multi-tiered application architecture. We will see that these are not completely unrelated.
Many academics and writers on the subject suggest that an approach that can address the business pressure for rapid change is by a multi-tier application architecture, which uses a loose coupling of collaborating services within and across tiers, to provide efficient scaling and re-use. Feedback from the early adopters of microservices suggests that they are most effective when built using a multi-tiered application architecture.
The author has called upon more than 30 years’ experience in application development and a continued keen interest in IT development, to document a journey through the many strands of this new and fascinating topic. This paper pulls together his research, thoughts and conclusions. Links to the many sources of information researched, can be found as footnotes to assist readers in their journey.
What will be seen is that with a multi-tiered architecture, together with a design approach of accessing constituent services via loosely-coupled APIs, you increase the likelihood of successfully addressing one of today’s major challenges: enterprises needing to develop applications in ever increasing numbers, users wanting to self-service and consume the services in multiple ways, and those users being frustrated by a perceived IT bottleneck.
What is the Problem?
It is often citied that established organisations are facing major challenges to their business in terms of growth, market share, and even their very existence, through the disruption caused by new digital outlets. This is driven by the fact that these outlets can combine and use sources of data in flexible and agile ways, in comparison to more established organisations.
In the photographic world, Kodak was dominant and its market share far outstripped the competition. However, they kept their focus on film technology (in spite of having invented digital photography) and maintaining their dominance in the supply chain, for the supply of photographic materials and chemicals. When this supply chain collapsed so did Kodak, reducing the organisation to a pale shadow of its former self. There is a current view that every business needs to be an IT business[1], using the information available to them to form new service revenue streams, or it will not be in business. Ignoring this could be comparable to following in Kodak’s footsteps. An interesting recent example is the way that Dixons Carphone Warehouse are innovating their organisation into a development delivery platform[2]
Although this view of the challenges facing today’s businesses appears to be reasonable, the author has no first-hand experience and decided to go looking for examples to support these assertions, beyond the frequent references to Netflix and Amazon, which are relatively young organisations where growth is naturally faster than that of long-established ones. The following case study appears to be more applicable to organisations supporting legacy IT and having to adapt to new business dynamics.
Case Study
While researching the rise and rise of Uber, a chain of links led to the following discoveries.
This press article London’s Addison Lee prepares for Uber challenge [3], describes how London’s largest fleet of private hire taxis found itself facing a second major competitor in the form of Uber (London’s licensed ‘black cabs’ being its first). In spite of a long history of using IT in innovative ways that had enabled its growth, this article states that Addison Lee (AL) appeared to be vulnerable to the new competition from Uber. So far, it has met this challenge with updated IT and a new version of its downloadable app.
What has AL been doing behind the scenes? One clue is found in a quote from: Adaptavist helps Addison Lee go full-speed with Agile [4], which states:
Addison Lee’s Technology Development team are focused on enhancing customer experience and on-boarding, delivering APIs for partners to consume, implementing a new microservices-based architecture for Addison Lee’s own allocation software, and supporting national expansion. Having responsive, Agile teams and processes to handle this volume of change is key.
How have they done this? This case study from MuleSoft, on how it supported Addison Lee[5] to re-engineer its IT, suggests that it came to some extent from using MuleSoft’s Anypoint platform. Two extracts are:
In just 6 weeks, Addison Lee securely unlocked their data and infrastructure with their first public API built on MuleSoft’s Anypoint Platform. This was specifically designed to support development of booking apps and web sites by third party affiliates and partners to incorporate the Addison Lee service.
The Mulesoft technology allows us to rethink how we connect our systems and expose our data and services in new ways to support a creative mobile strategy.
As will be seen in this document, MuleSoft is one of a number of sources promoting the need for a multi-tier API-based application architecture, in order to support the rapid developments required to stay competitive, as organisations are challenged by existing competitors and disruption from new ones.
What is a Multi-tier Architecture?
The above case study serves to illustrate the major challenges facing many of today’s businesses:
- Technologies, such as SaaS, mobile and IoT, have dramatically increased the number of endpoints to which we must connect
- The frequency with which these technologies change is greater than for established technologies.
Gartner identified that the traditional model of IT, which is mostly concerned with accuracy and availability, does not address the needs of businesses wanting to benefit from the ability to support opportunities quickly and with some degree of experimentation – speed and agility being paramount. To describe this, Gartner defined the term bimodal IT[6].
One approach to this dichotomy has seen some lines of business create their own solutions because ’IT’ is seen as being too slow to deliver. In the long run, the accumulation of business-led initiatives can only end in tears.
This is highlighted by Bernard Golden on page 2 of his article on bimodal IT[7] as “I don’t just want to have a mobile application that lets me interact with a loan officer, I want to use it to submit my documents, track my loan progress, and even sign off on the loan”.
An effective solution to this comes in the form of an application architecture that uses multiple tiers to handle different speed-of-change modes. There are a number of descriptions that can be found for the benefits to be had from a multi-tiered application architecture. Some recognise three tiers and others four; there is in fact no difference in the architecture – the three-tiered model does not count the actual Client as a tier.
In the diagram below, the value range in each tier is a typical frequency of change in weeks – see MuleSoft’s paper on API-led Connectivity[8].
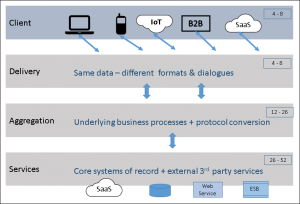
Figure 1: A 4-tier application hierarchy, with typical frequency of change in weeks
Why is a multi-tier architecture so effective?
In a nutshell, bimodal IT is supported through loosely-coupled services that are accessed using APIs which interoperate within a tier and across tiers.
An API encapsulates a component or service behind a façade, which defines a contract to provide a well-defined response to a given set of input values. The loosely-coupled nature of APIs is often described as being out of process, meaning that the invoking process has no knowledge as to where the invoked API resides. The most common API implementation is an HTTP-based REST / JSON call.
The following diagram has added a number of API/Service icons to illustrate this. Note: the connecting arrows in and between the non-Client tiers, illustrate connections in principle, to reduce clutter in the diagram.

Figure 2: Tiers with APIs
The Aggregation and Services tiers are shown as invoking APIs within the same tier and between tiers. For example, one API in the Aggregation tier could be orchestrating the invocation of other APIs in the same tier, and possibly, others in the Services tier.
In the Delivery tier, each API is shown as being one-to-one with a single type of Client. This is to illustrate the fact that each kind of client will have different capabilities and volumes of data per API call. Anecdotal evidence suggests that most APIs in this layer are best developed on a one-to-one basis for a given type of client device. One aim, in particular, is to avoid ‘chatty’ dialogues, in which a client has to make many service calls rather than one, for any particular function.
What is a Microservice?
There is no completely accepted definition of a microservice. A short definition that is frequently seen is:” a microservice is designed to do one thing very well”.
Most articles on the topic start with a reference to Microservices – a Definition of This New Architectural Term by Martin Fowler and James Lewis[9], which was published in 2014, and is frequently described as one of the seminal publications on microservices. They describe a microservice, in more detail, as:
An approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API.
…
These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies.
Why Use Microservices?
A concise description that can be found in Seven Microservices Anti-patterns[10], provides a very interesting description using hindsight to describe mistakes made during its author’s time on early microservices projects. It reminds us that the following points have always been the most common business reasons for any architecture – use of microservices being no exception:
- Improved Agility: the ability to respond to the business needs in a timely fashion so that the business can grow
- Improved Customer Experience: improve the customer experience so that customer churn is reduced
- Decreased Cost: reduce the cost to add more products, customers or business solutions
Monolithic applications
Fowler and Lewis compare microservices with traditional Enterprise Applications, which they describe as monolithic. This term is actually describing the reality of making changes, no matter how small, where it means that the whole ‘thing’ of which the changed ‘bit’ is a part, has to go through the all of the testing levels and then get a slot in a deployment cycle.
For a Web application, even where you have separation of concerns between HTML pages (View) and a shared database (Model), which are stitched together by server-side functionality (Controller), the unit of deployment is still a single executable. This has the above-mentioned constraints for change and deployment. The more recent ESB technology still exhibits a similar high ‘drag coefficient’ for making small changes – which renders them monolithic in this context.
Characteristics of a Microservice
By contrast, using a microservice architecture, the same functionality would be built as a collection of small services, each running in its own process, communicating via lightweight mechanisms. Each service is independently replaceable and upgradeable. The most common mechanism being a loosely-coupled REST API request, which has a well-defined input and output. How this is implemented is, in principle, of no concern to the invoker.
Fowler and Lewis9 describe microservices as having the following characteristics:
- Componentisation via services: a unit of software that is independently replaceable and upgradeable.
- Organised around Business Capabilities: involves components in all tiers
- Products not Projects: if you build it, you own it and you run it
- Smart endpoints and dumb pipes: applications built from microservices aim to be as decoupled and as cohesive as possible
- Decentralised Governance: build using multiple technology platforms – using most appropriate ones
- Decentralized Data Management: use the idea of Domain-Driven Design with a Bounded Context[11]
- Infrastructure Automation: automation of testing and deployment; scaling of deployment
- Design for failure: tolerate failure in called services; restore failing services quickly via monitoring
- Evolutionary Design: increase granularity of components when identified and required.
A view taken from the perspective of microservices-in-action, can be found in the article Three Keys to Successful Microservices[12], which presents a different take on the characteristics of a microservice:
In summary, using microservices means replacing a monolithic application architecture with a set of small, single-function, loosely coupled applications that communicate through APIs, and are easily assembled into bespoke experiences for distinct users or devices.
- Applications are collections of functionalities that are simultaneously consumed by many different types of users and client devices.
- Microservices are the building blocks of modern applications.
- Microservices components are loosely coupled, accessed using APIs.
- Deployment is based around the concept of immutable containers[13] (analogous to shipping containers).
How do Microservices and a Multi-tiered Architecture Fit Together?
The short answer, according to AppDynamics[14] is …… extremely well.
In this e-book on building microservices, there is a chapter on Migrating to Microservices, which strongly recommends the adoption of a four-tier architecture as the basis for this. It uses the ideas described above, makes references to Mobile Needs a Four-Tier Engagement Platform (Forrester)[15] and It’s Time to Move to a Four-Tier Application Architecture (NGINX)[16], in order to illustrate the synergy between APIs, multi-tiered architecture and microservices.
The following diagram is an augmented version of the previous one. The server-side tiers are shown in a 3D-like manner as a reminder that different technologies can be used to implement APIs / services in a given tier. Tiers are a logical concept and do not represent a particular technology. In a microservices world, the team developing an API are free to choose the most appropriate technology to ‘get the job done’.
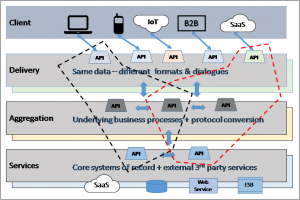
Figure 3: API-led services, with a re-used API
One rather nice analogy that was suggested to the author[17], is a wine rack. Each tier in the rack holding wines of a specific type (single estate / regional / supermarket), with the wines in any tier being from different producers. After a bottle has been consumed, it could be replaced by a bottle of the same type – from the same producer or another. When viewed as a ‘service for a party’, bottles from all tiers can be chosen as required.
Re-use and Change when using an API-led Tiered Architecture
In the above diagram, two Delivery-level APIs are illustrated by using a dashed-line to surround their constituent APIs in other tiers, in order to show the implementation of their required business functionality. Notice that there is one API in the Aggregation tier that is used by both.
What happens when this common API is changed so that in addition to version 1 (V1 – now deprecated), a new version (V2) is available? As all of the APIs are loosely coupled, the choices for the two Delivery-level APIs are:
- Continue to use V1
- One of them uses V1 and the other uses V2
- Both change to use V2
The choice being based on whether the change to the common API was made to support a change in the requirements of these Delivery-level APIs or not. Versioning is usually handled by making the version to be a part of the URL: https://xxx.api.com/apiname/V1/… At some point in time, the common API will indicate that its V1 will be removed, and any APIs using it will have to move to a newer version.
Re-use and Change when using Microservices
In the world of microservices, a different set of considerations is involved. It was stated earlier that the deployment of microservices is based around the concept of immutable containers – meaning that for a given version, it cannot change.
Let the dashed lines in the previous diagram become solid in order to create a visual representation of the service as a container. What happens to the shared API? Since a fundamental tenet of microservices is re-use, it does not make any (much?) sense to duplicate it to be in both containers. One obvious solution is to create a new microservice for just the common API. This is illustrated in the diagram below.
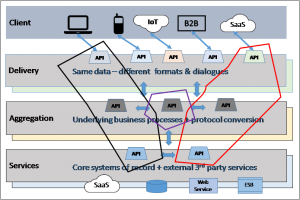
Figure 4: Two client-facing containers, that both use a shared container
This solution allows all of the three deployed containers to be scaled, as and when demand requires.
Changes to a Microservice
The rationale is almost the same as described for a change to a shared API. Since a container is regarded as immutable, this implies that any change will require a new version to be created. This is illustrated in the following diagram where the shared container has two versions: V1 still used by one container, and V2 being used by the other.
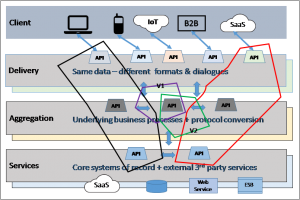
Figure 5: Two client-facing containers, that using different versions of a shared container
Eventually, the deprecated V1 will be removed – requiring all containers that invoke it to be updated.
How do Microservices differ from an API-led Architecture?
An API-led application architecture has a few rules regarding separation of concerns which relate to the nature of the tier in which an API exists; along with conventions and sound design practices for APIs.
Compare this with the kind of well-defined characteristics that we have already seen for microservices, such as the list from Fowler and Lewis9, above, which they describe in the introduction as (emphasis added).
In short, the microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies.
This is a radical departure from anything that this author has seen before.
Using a Managed API
A managed API uses a Gateway to provide security along with facilities such as: access-rate throttling, limiting the number of API calls made during a specified elapsed time, usage statistics (who, when, how much), versioning and an ‘API store’ for discovery.
In the Delivery tier all APIs should be accessed via a gateway, where security will be of primary importance. It is in the gateway that the client has to establish its identity (authentication) by providing credentials that can be validated, and to determine the scope of functionality available to it (authorisation). The most commonly used authentication method for access via a managed API being OAuth 2.0[18] [19]. The end result of OAuth 2.0 authentication is an access token [20], which is also used to define the scope of the client’s access rights for an API. This token can be passed on by the gateway to other ‘internal’ APIs.
The million-dollar question is: should APIs in the Aggregation and Services tiers be accessed via a gateway? The answer is, of course… it depends. Using a gateway increases security (which may be paramount in some cases) and can be used to provide some or all of the gateway facilities described above. However, it also creates an additional ‘hop’ between all calls, which could result in unacceptable response times.
The top results from an internet search on the topic of securing internal REST APIs (those behind a firewall and/or a client-facing API gateway), suggest that internal REST APIs should always have some measure of protection, whether for a microservice or not.
A very recent book (June 2016) on microservices architecture[21] has a section titled The Need for an API Gateway. On page 98 it states:
Sometimes, certain microservices are deemed “internal” and are excluded from the security provided by an API Gateway, as we assume that they can never be reached by external clients. This is dangerous since the assumption may, over time, become invalid. It’s better to always secure any API/microservice access with an API gateway. In most cases the negligible overhead of introducing an API gateway in between service calls is well worth the benefits.
In the article Seven Microservices Anti-patterns10 referred to earlier, item 7 is titled Building a gateway in every service. This describes its author’s experiences of not having an API gateway, and the problems that ensued when they added gateway-like facilities into each service. The recommendation is:
Invest in API Management solutions to centralize, manage and monitor some of the non-functional concerns, which would also eliminate the burden of consumers having to manage several microservices configurations. An API gateway can also be used orchestrate the cross-functional microservices, that might reduce round trips for web applications.
This is illustrated in figure 6, taken from Seven Microservices Anti-pattern10:
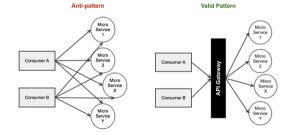
Figure 6: Using an API Gateway with (micro)services. (Source Vijay Alagarasan)
Adopting Microservices
There is a lot of material ‘out there’ on this topic – both academic and feedback from actual experience. This section provides some pointers from the material discovered during the creation of this document. The author presents this as an aid to ‘get you going’. As such, the often-stated golden rule of ‘products not projects’ is not considered – after all this is about an organisation taking its first steps. Products will follow on once the early lessons have been absorbed.
Much of what is described here is also valid for the first steps in embarking on a multi-tiered, component-based approach to developing applications, because when starting out, there is not much difference.
Why and When? (Should Microservices be Adopted)
For a start-up organisation, the answer would be: why not? When you have a green-field opportunity, microservices represent the best approach currently available.
For established organisations, the picture is more complicated (though ’why not’ does have a place).
- Are you facing the kind of threats to your existence that a disruptive newcomer such as Uber can present? If you do, then the answer is: do it now and get experienced support to assist you.
- Is your business making requests to IT to provide new services for devices in the Client tier ‘now’, and the best that IT can offer is to put these requests into a queue? If it is, then IT should establish a partnership with the business, in order to adopt microservices for the most pressing demands.
- If no such pressure appears to exist, then there in an onus on IT to begin the adoption of microservices as the response to changes and enhancements to existing systems. This will surely serve the organisation well for when the use of microservices is needed.
How?
The following headings contain extracts from InfoWorld – Three keys to successful microservices12 above: “A successful migration to microservices requires componentization, collaboration, reliable connections and controls.”
Create Components
Select a component from an existing application that can be easily separated into a microservice. Begin by defining a RESTful API to access this service, then plan and create an implementation using whatever development language and platform your development team is most comfortable with.
Wherever possible, keep it simple by using the tools you already know, without compromising the principles defined in this document. Your goal should be to create a microservice with an integrated process for development, test, and deployment, bringing you well along the road toward continuous delivery.
Collaborate
Share the lessons learned during the pilot program with the entire development organisation. When you plan to decouple your application into smaller, independent services, expect to split your existing teams into smaller, independent units. Within each team, you must have the full set of skills needed to create a simple service (presentation, logic, data), and each team should take responsibility for the development and test framework of the services they create.
Between teams, collaboration centres around two items:
- technology standardisation and API contracts.
- provided that this contract is comprehensive and the team adheres to it, the team is free to re-implement or refactor the internals of the microservice at will.
Connect
Complete the application and connect to users in a real-world scenario. The successful delivery of an application involves much more than the creation of the constituent components. These components must be connected and a presentation layer and additional services layered in, then the completed application must be delivered to users.
More on ‘How?’
A late arrival on the scene (while the author was researching for this paper), is Microservices: What are They and Why Should You Care? [22] It describes many of the topics in this document through the use of a case study that describes the development of a minimum product as a monolithic application that goes live, and the problems that ensued as it was changed and enhanced over time. It concludes by describing how microservices came to the rescue and the lessons learned.
Concerns
Microservices and the multi-tier application architecture described in this document can appear to be more complex than monolithic applications. It could be perceived that you are increasing the overall complexity of your environment. Think of it this way, while you may be separating concerns from a code and functionality perspective, you are creating a large web of dependencies that now need to be accounted for in all tiers of an application[23]. However, tooling is available to manage and account or this complexity.
Because the author has spent many years in application development, there is one specific item of concern that he wanted to understand in more detail – the use of an independent data store for a microservice, resulting in data becoming de-normalised and then keeping changes synchronised across data stores.
The use of a separate data store per microservice
This idea feels inherently dangerous, in that there must be a risk of ‘the same’ data becoming inconsistent across microservices. Refer back to the comments by Bernard Golden on bimodal IT on page 4, where he mentions wanting consistency in his banking data.
A related concern is: what happens when a business transaction fails that involves updates via multiple services? As there is no way of providing two-phase commit support, how can you undo changes already made? The author’s research has found that there are design approaches and patterns that can be used to keep data consistent… ultimately.
That last word is significant. The reason is that in order to achieve the advantages of flexibility and speed of change, one casualty is that some items of data can be wrong for a (short) time. For instance, if an order for an item fails at the payment step, the stock level of that item will be recorded as lower that it actually is. This might affect other orders until the stock level is corrected. An interesting tale on this topic can be found in Starbucks Does Not Use Two-Phase Commit[24]
In some cases, there might be critical items or areas of data where this situation is forbidden. In these cases, some degree of flexibility for microservices implementation might have to be sacrificed.
Resolution
The following design approaches taken together should ensure data consistency.
Domain-Driven Design (DDD)
Different parts of a business often have differing views of the same business entity. A Customer is probably the most common example of this, where say, the Sales Department and Spares Department use items of data that are unique to each. When an organisation uses a common relational database for all applications, domain models will try to cater for all needs. This can make them hard to use, usually from being over-complicated, and occasionally from being at too high a level of abstraction (e.g. Customer being a specific case of Party). DDD in essence, means deriving a domain model just for a specific business area. This is illustrated in the following diagram from Martin Fowler, BoundedContext[25].
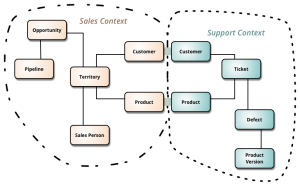
Figure 7: Bounded Contexts (source, Martin Fowler)
In the above diagram, it is clear that the Customer and Product entities in each separate domain, will share some attributes with their counterparts, such as Customer Number, Customer Name, Product Number. These must be kept consistent.
DDD and Microservices
Continuing with the above diagram as the basis for an example where there are separate Sales and Support Department microservices. It is almost self-evident that the answer is: each microservice will have a data store whose contents match its own domain model.
However, what about attributes that are duplicated in each domain? These could be changed by either application (a name, an address), or a value derived from processing in one domain, that is required by the other. For instance, a Product in Sales might need information on defects reported for a Product.
A solution frequently found is to use messaging, especially publish/subscribe. In the above example, changes made to attributes needed by other microservices could be published to a message broker, which will then be delivered to all microservices that have subscribed to receive the updates. The term Master Data Management is used to describe such a facility, along with products designed to synchronise data in ‘silos’[26].
Multi-service update failure
This situation was mentioned at the start of this topic. It can only be handled through a compensation mechanism where, in the event of a failure, changes already committed are reversed. This requires that the data required to restore the data to its pre-update state, has to be held in some way, somewhere.
One solution is known as the Saga (architectural) pattern for failure management, which was defined back in 1987. It relates to long-lived transactions and defines a mechanism for handling failures in distributed data updates, such that the state of all the components gets restored to their original state via a sequence of compensating operations. This state machine mechanism is described in Microservices Architecture2020, on page 78, and it refers you to this example by Clemens Vasters[27] for an explanation of the pattern. At the heart of it is the concept of a Routing Slip[28] that is attached to all steps in the sequence. After each successful operation, details are added to the slip, which point to its compensating operation. When a step fails, after undoing local changes, the routing slip is passed backwards along the chain so that each step undoes its own changes.
The beauty of this is that it provides an architectural pattern to form the basis for designing how you want to implement the handling of failures in all distributed applications and microservices. The alternative being the proliferation of unique approaches within each application or microservice – each being a potential source of confusion and error, for ever!
Existing services should not be changed in order to cater for taking part in a distributed update. It is suggested that a new service be created to wrap each existing service. The wrapper service will handle the routing slip processing in both directions.
Enablement Support Group
The Database Administration (DBA) role is one that emerged with the first relational database products. In a similar way, the author sees a strong need for an equivalent function for ensuring that mechanisms are in place to reduce the probability of confusion and errors creeping in.
Here are instances where an Enablement group would have the knowledge to:
- Ensure that data attributes that need to be kept consistent between services are identified and mechanisms implemented to do this.
- Ensure that when updates that are distributed across services, that they implement whatever mechanism has been chosen to back out changes in the event of failure, such as the Saga
- Assist in the provision of information about existing APIs / services, so that new applications increase their chances of discovering which of them might be suitable for re-use.
Implementation Suggestion
Do not create an Enablement Group with fixed set of people. This group should be somewhere that people in project teams pass through, with a typical duration of 6 to 12 months. Each person will bring their knowledge and skills to the group. They will pass on their experience of good practices. When they leave, they will take a wider knowledge of the development environment with them to whichever team they join; potentially returning at a future date, having enhanced their knowledge and skills in the meantime.
Conclusions
- Ensure that the benefits of moving to a multi-tier or microservices application architecture outweigh the costs, and that you are doing it for the right reasons. Re-visit this as the use of this architecture expands, until it can no longer be challenged.
- Whilst separation and re-use are clear benefits of a microservices approach, it needs to be managed via appropriate tooling.
- Complexity due to separation of concerns, must be controlled in order to understand what services are going to change frequently, those that are likely to be stable and used often. It is crucial for both situations to be managed.
- Avoidance of Technology Lock-in is a key principle, as is allowing developers to use favoured tools and BYO solutions.
- Allow your technical teams to be centres of enablement with experience of reuse, patterns and useful design artefacts to assist in the development process.
A final word from the AppDynamics e-book7:
Microservices are not a panacea. There are potential drawbacks such as code duplication, mismatch of interfaces, operations overhead and the challenge of continuous testing of multiple systems. However, the benefits of creating loosely coupled components by independent teams using a variety of languages and tools far outweigh the disadvantages. In our current computing environment, speed and flexibility are the keys to success – microservices deliver both.
A word about the author;
John Ormerod Educated at Queen Mary College London – with a degree in Mechanical Engineering, he spent 30 years at IBM mainly in Services and technical pre-sales, before moving into the world of the independent software development and Integration community. For the past 2 years John has been working as a Technical Consultant in the world of API development and Management for W3Partnership.
About W3Partnership
W3Partnership is an independent provider of business consulting and integration expertise, offering strategic consulting and Cloud Integration services at the point where business and technology converge. W3Partnership has a proven methodology for implementing Integration Platforms and deploying to Hybrid Cloud environments. This approach has been developed and honed over a large number of engagements with clients in the Government, Retail and Finance Sectors. To find out more about W3Partnership visit www.w3partnership.com or email at info@w3partnership.com.
[1] See: Every business will be a software business
[2] See the following video from Dixons Carphone Warehouse
[3] Daily Telegraph 7 July 2016
[4] Adaptavist helps Addison Lee go full-speed with Agile
[5] MuleSoft – Addison Lee (Case Study)
[6] Gartner’s view on Bimodal IT
[7] What Gartner’s Bimodal IT Model Means to Enterprise CIOs
[8] API-led Connectivity: The Next Step in the Evolution of SOA (MuleSoft)
[9] Microservices – a definition of this new architectural term
[10] Seven Microservices Anti-patterns
[12] Three Keys to Successful Microservices
[13] What are containers and microservices? (Computer Weekly)
[14] How to build (and scale) with microservices
[15] Mobile Needs a Four-Tier Engagement Platform (Forrester)
[16] It’s Time to Move to a Four-Tier Application Architecture (NGINX)
[17] Marcus Langford, W3Partnership
[18] OAuth 2.0 Wikipedia entry
[19] OAuth 2.0 – Spec and Beginner’s Guide
[20] An access token (also called a bearer token in OAuth 2.0) can be permanent, or have a limited life, after which the server will negotiate a renewal with the client.
[21] Microservice Architecture – aligning principles, practices, and culture
[22] Microservices: What are They and Why Should You Care?
[23] Thoughts on Migrating to a Microservices Architecture
[24] Starbucks Does Not Use Two-Phase Commit



I wonder why i stumbled upon this blog so late. This is quite succinct but perfectly written. It has almost everything well put except circuit breaker patter, async vsy synch, IPC/messaging across microservices
Very well written
Thank you for your kind words. Watch out for the 2nd and 3rd in the series coming out soon.
Hi ‘a’
Thanks for your supportive feedback. You ask ‘why?’. Could be the old adage “when the teacher is ready the student appears” or maybe it’s the other way round. 🙂
I felt that I had to stop somewhere – not that topics you mentioned were in-plan or appeared over the horizon during my quest. I’ve had a quick search and for the benefit of other readers, these topics appear to be well covered in:
https://dzone.com/articles/building-microservices-inter-process-communication
Note: the links to ‘Richardson…’ do not work, but this one does and looks worthwhile (I think I overlooked it):
https://www.nginx.com/blog/building-microservices-using-an-api-gateway/#product-details-scenario
Regards, John
BTW: Marcus’s reference to Parts 2 and 3 are for my series on open source development tools that I have found useful.
Thank you Johan and Marcus. If the part 2 and 3 are out, have I overlooked the links for them or they are not yet out? If they are out, please share the links for them. I had a hard time grasping the ability to be able to appreciate the 4 tier thing as it was not so well expressed. This write up did that quite well. I even sent the link for this blog to 2 of my colleagues. There is lot of good literature on these things but it is too scattered and requires patience to read and then understand what to read further. This blog is a good kickstart to know enough to figure out where to go from here!
I meant the 4 tier thing was not so well mentioned in other blogs and this one cleared it up quite well for me
Thank you for your interest in these articles. The second part of these articles is now published and can be found here.
http://w3partnership.com/Blog/2017/01/05/open-source-testing-tools-for-api-development-part-2/
If you are interested in API Management, why not attend our webinar on the 15th February. You can register here.
http://w3partnership.com/webinar_API.html
Please keep up the dialogue with us, as your feedback helps improve the services we offer.
Marcus Langford
Chief Operating Officer
W3Partnership
Marcus@w3partnership.com